Thoughts on data science, statistics and machine learning.
More Pixels
Someone must have thought, likely with good reason, that more pixels on larger screens is a good idea. Then, someone else must have thought that if it’s a good idea somewhere, it must be a good idea everywhere.
It’s probably for the same reason that I can’t find a new car with tactile switches anymore. Everything’s got touch buttons. In my car, nothing other than the steering wheel has any physical feedback. To check if I’ve successfully changed the A/C mode, I either have to wait until I feel the temperature change or I have to take my eyes off the road. And don’t even get me started on the massive ‘infotainment systems’. I don’t understand how we came to a place where more expensive cars meant fewer physical buttons and huge touchscreens.

Beer on the Mekong - Growth, Discovery and Creativity in 2025
It’s easy to dismiss New Year’s Day as just another revolution around the sun - an arbitrary checkpoint which carries no inherent meaning. But then all checkpoints and milestones are arbitrary. Who’s to say that 17 year and 11 months old teenager is significantly less mature than an 18 year-old adult? We have milestones because they’re convenient. So in the spirit of benchmarking convenience, perhaps it is not such a bad idea to stick to resolutions, goals and plans.
Do Feed the Trolls
I’m trying to build a habit of writing about things that trigger me. For one, I’m sensitive, so there’s an infinite supply of things to write about. Moreover, writing helps clarify what you’re really triggered by. People who have a regular journaling habit say that it’s revelatory and therapeutic.
This is about the recent Kamra-Aggarwal debate
spat. It’s not about who’s in the
wrong - we all know the answer to that. It’s about how people have been reacting
to the episode.
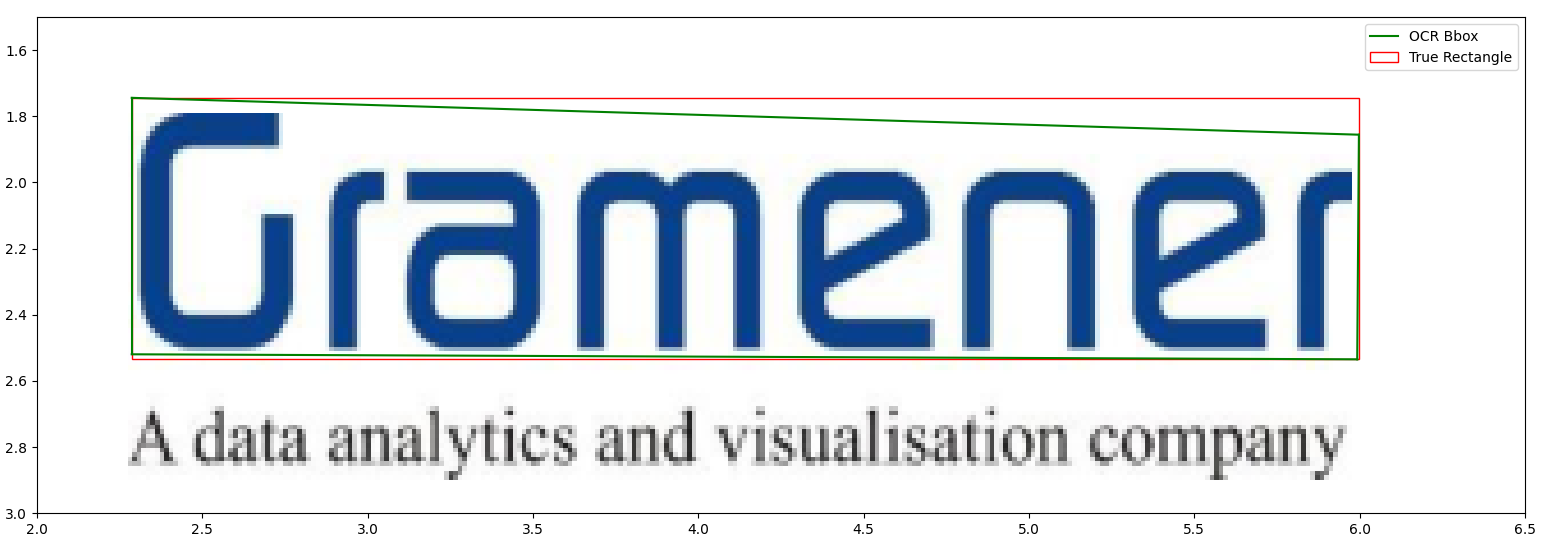
Misconceptions about OCR Bounding Boxes
Over the last year, I have been working on an application that auto-translates documents while maintaining the layout and formatting. It has many bells and whistles, from simple geometric tricks to sophisticated gen-AI algorithms and microservices. But basically, the app performs the simple task of identifying text in documents, machine-translating them, and reinserting them such that the output document “looks” like the input.
Most documents that my app has to process are PDFs. PDFs are ubiquitous but notoriously hard to analyze. Since pretty much every app is capable of producing a PDF file, its layout can get particularly nasty. Moreover there is no single semantic description of what comprises a document - e.g. an email is as much a document as a boarding pass. Who’s to say that a selfie is not a document? This means that my users can upload almost anything into the app, and as long as it has some text, it ought to be serviceable.